Diff Algorithms: Myers vs Hunt-McIlroy vs Patience
Explore the algorithms behind version control and text comparison. Learn how Myers, Hunt-McIlroy, and Patience diff algorithms work, their trade-offs, and when to use each approach.
Diff algorithms power the essential functionality developers rely on when comparing different versions of code. First introduced by Paul Heckel in 1978, these computational methods have since evolved significantly to become fundamental tools in modern software development. When working with version control systems, we often take for granted how our changes are displayed, but the choice of algorithm dramatically affects readability and accuracy.
Git, the widely-used version control system, supports four distinct diff algorithms: Myers, minimal, patience, and histogram. The default Myers algorithm, developed by Eugene W. Myers in 1986, processes differences efficiently but doesn't always produce the most human-readable results. Additionally, the Hunt-McIlroy algorithm represents one of the early innovations in text diff algorithms, while the Patience algorithm, created by BitTorrent inventor Bram Cohen, takes a different approach by matching unique lines between file versions. Furthermore, the widespread adoption of Git has significantly popularized the Universal diff format, making it the standard for file comparison today.
In this article, we'll examine why different diff algorithms matter, how they work, and when to use each one for optimal results. By understanding these tools better, we can make more informed choices about which algorithm best suits our specific needs.
Understanding the Role of Diff Algorithms in File Comparison
Image Source: Tecmint: Linux Howtos, Tutorials & Guides
"Diffs are the language through which you understand how things have changed in your software." — James Coglan, Software engineer and author of 'Building Git', expert on Git internals
What is a diff algorithm?
At its core, a diff algorithm is a set of instructions that compares two sets of code or text to identify differences between them. Essentially, these algorithms find the minimal set of edits needed to transform one text into another. The output, often called a "patch" or "delta," lists the changes between two files in a standardized format that can be applied to regenerate either version.
Most diff algorithms solve the "longest common subsequence" (LCS) problem – finding the longest sequence of items present in both original sequences in the same order. This approach helps identify which parts remain unchanged, allowing the algorithm to isolate what was added, modified, or deleted.
Why diff algorithms matter in version control
Diff algorithms provide several critical benefits in software development. First, they enable efficient identification and display of changes between versions of files or documents. Second, they facilitate tracking modifications over time, making collaboration possible across distributed teams.
Moreover, these algorithms determine how changes appear to developers. A poorly chosen algorithm might display changes in a confusing manner, making code reviews more difficult and error-prone. Consequently, the right algorithm can highlight differences at a granular level, enhancing clarity and accuracy in reviewing changes.
Without effective diff algorithms, version control systems would need to store complete copies of each file version – an inefficient approach that would make tracking history practically impossible for large projects.
Common use cases in Git and other tools
The git diff command represents the most common application of these algorithms, showing changes between:
Working tree and staging area
Staging area and latest commit
Two arbitrary commits
Different branches
Two files on disk
Git supports four distinct algorithms through the --diff-algorithm option:
Myers (default): Works well for most scenarios, providing readable output with reasonable performance
Minimal: Creates the smallest possible diff, useful for comparing large files
Patience: Better represents code changes, particularly when dealing with refactored or reordered code
Histogram: An improvement on Patience that handles unique common elements
Besides Git, diff algorithms power code review tools, automated testing frameworks, and file synchronization utilities. They're also essential in patch generation tools that create update files containing only the changes instead of complete replacements.
Myers Algorithm: The Default Choice in Git
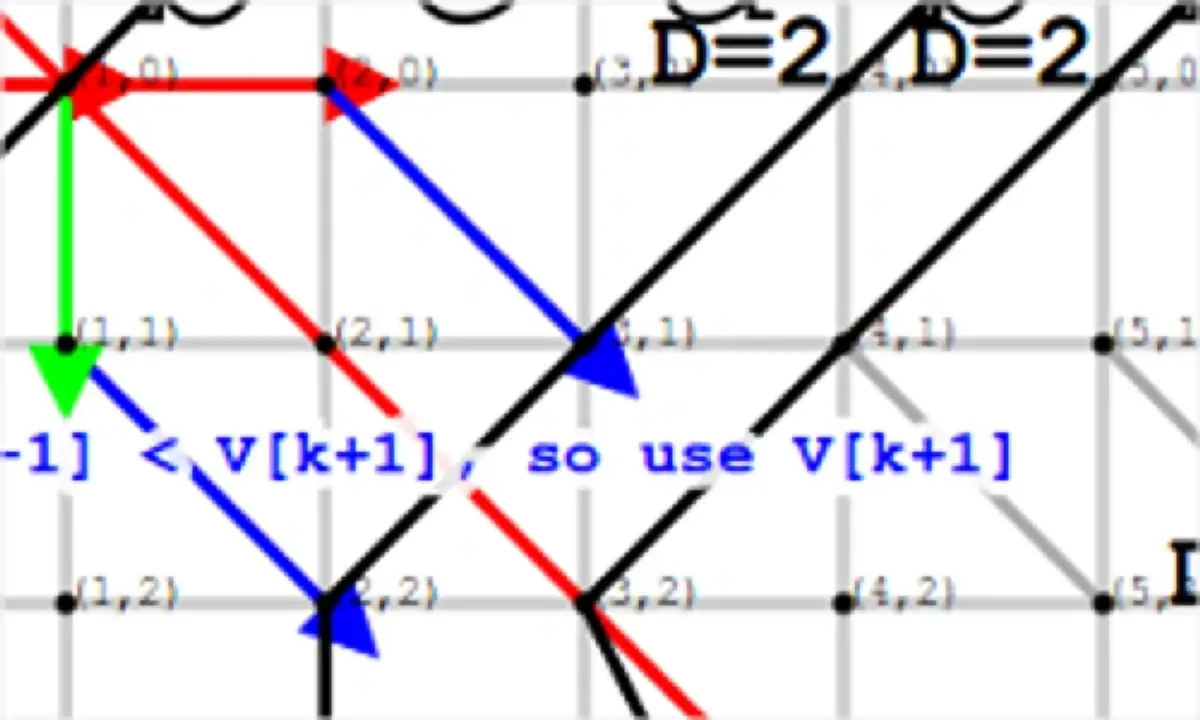
Image Source: Robert Elder - Robert Elder Software Inc.
Eugene Myers' algorithm stands as the backbone of Git's default diff implementation, offering an elegant mathematical approach to comparing files. Originally introduced in 1986, this algorithm transforms sequence comparison into a path-finding problem within an edit graph.
How Myers algorithm finds the longest common subsequence
The Myers method represents file comparison as a grid where horizontal moves indicate deletions, vertical moves represent insertions, and diagonal moves show matches. Hence, the algorithm seeks the shortest path from the top-left to bottom-right corner of this graph, corresponding to the minimal edit script. It accomplishes this through a layered exploration strategy, introducing k-lines (where k = x - y) to track diagonal paths. Firstly, it searches diagonally for matching elements ("snakes") before encountering mismatches that require edits.
Strengths: Speed and general-purpose usage
Myers excels primarily because of its O(ND) time complexity, where N represents the combined sequence lengths and D indicates the minimum edit distance. This makes it notably efficient when comparing similar files. In fact, for most practical situations, it runs two to four times faster than earlier implementations. During ordinary usage, the algorithm tries to consume as many matching lines as possible before making changes, thereby avoiding certain mismatch problems.
Limitations: Readability and matching trivial lines
Nonetheless, the algorithm sometimes produces suboptimal diffs when handling refactored code. Its greedy nature can occasionally match trivial lines inappropriately rather than identifying higher-level structural changes. Additionally, under certain conditions, Myers' implementation requires heuristics to limit computational costs, potentially sacrificing optimal output for very different files.
Hunt-McIlroy Algorithm: Early Innovations in Text Diffing
Long before Git existed, the computing world witnessed the birth of the first practical diff algorithm. In 1976, Bell Labs researchers James W. Hunt and Douglas McIlroy published their groundbreaking approach to file comparison. This seminal work would lay the foundation for decades of text comparison tools.
Historical context and origin at Bell Labs
Initially described in a technical report, the Hunt-McIlroy algorithm emerged from the collaborative efforts at Bell Labs. Hunt refined an idea proposed by Harold S. Stone, implemented the first candidate-listing algorithm, and integrated it into McIlroy's framework. Subsequently, Hunt co-authored a modified version with Thomas G. Szymanski the following year, leading to what's sometimes called the Hunt-Szymanski algorithm.
Focus on k-candidates and dynamic programming
The algorithm's primary innovation was its focus on "k-candidates" - pairs of indices where the two files have common elements. Specifically, these are positions where breaking the match would shorten the longest common subsequence. By processing only these essential matches instead of every possible comparison, Hunt-McIlroy dramatically reduced computational requirements. For instance, comparing two 10,000-line files requires approximately 20,000 operations with Hunt-McIlroy versus 100 million with classic dynamic programming—a 5,000× improvement.
When Hunt-McIlroy produces suboptimal diffs
Although revolutionary, the algorithm has limitations. The classic version uses significant memory (an MxN square), requiring about 100MB for comparing two 10,000-element strings. Furthermore, the solution found might not always be optimal, depending on the strategy used to link k-candidates. In worst-case scenarios, its time complexity reaches O(mn log m), though practical performance is typically much better.
Patience Algorithm: Prioritizing Human-Readable Diffs
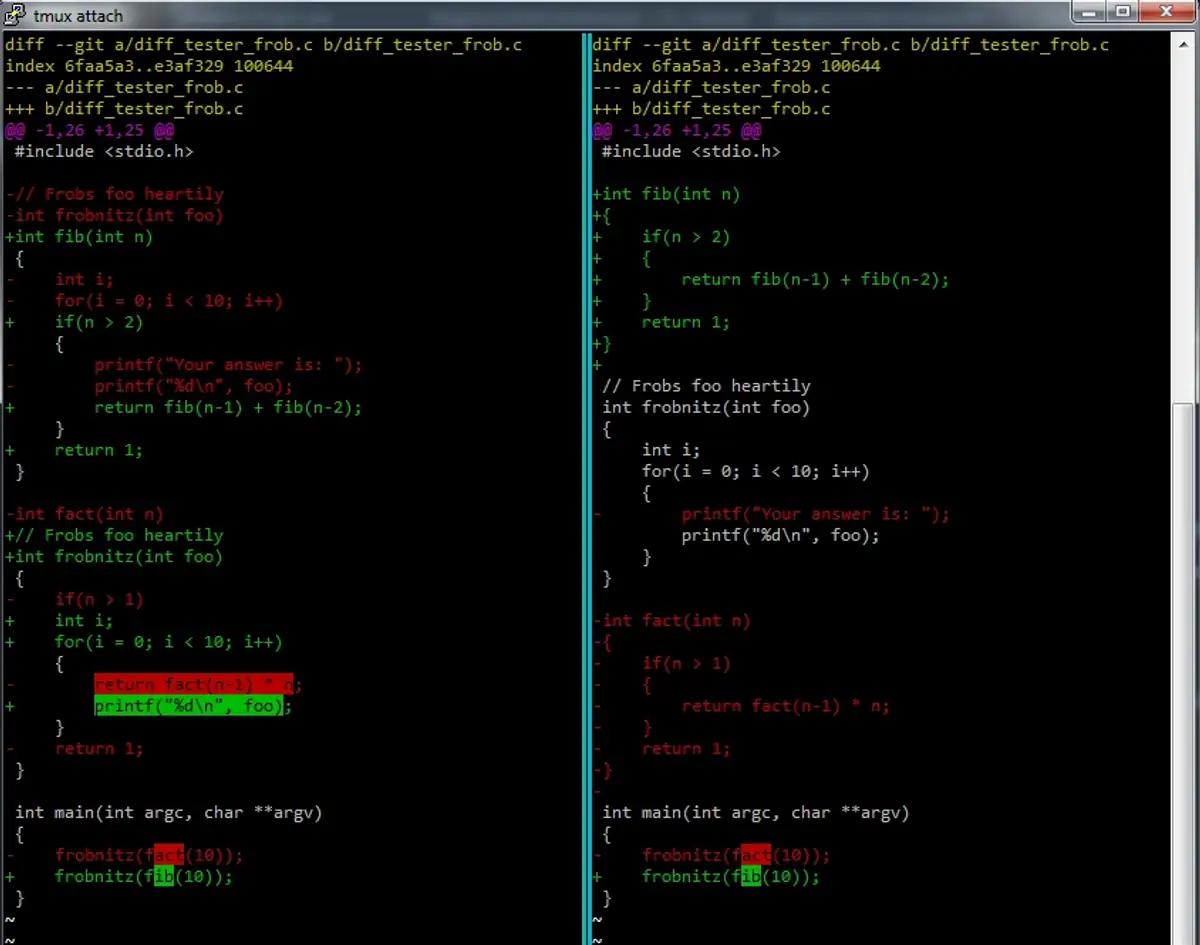
Image Source: Stack Overflow
Created by BitTorrent inventor Bram Cohen, the Patience diff algorithm takes a fundamentally different approach to comparing files. Unlike Myers, it prioritizes human readability over minimizing edit distance, making it ideal for reviewing complex code changes.
How patience diff uses unique line matching
Patience diff identifies lines that occur exactly once in both files, considering these as "signature" lines that likely represent meaningful content. Thereafter, it matches only these unique lines, creating anchor points to divide the files into smaller segments. Each segment is recursively processed until no unique matches remain, at which point it falls back to Myers.
Patience sorting and longest increasing subsequence
The algorithm's name derives from its use of patience sorting to find the longest increasing subsequence among matched lines. Initially, a card game analogy applies—cards (lines) are dealt into piles according to specific rules, ultimately forming sorted stacks. Given these points, this approach effectively handles situations where matched lines might cross in the comparison.
Why it works better for reordered or refactored code
Patience diff excels with refactored code primarily because it doesn't match trivial lines like lone brackets, blank lines, or common boilerplate. Consequently, this preserves the structure of important content such as function declarations. By focusing on unique lines, it generally produces cleaner, more intuitive diffs for complex changes.
Comparison with Myers in real-world examples
In practice, Myers often creates confusing diffs by matching unrelated blank lines or curly braces. Conversely, patience diff typically generates more readable output that better reflects developer intent.
git config --global diff.algorithm patienceThis small configuration change can dramatically improve code review experiences. Try our Text Compare tool to see these diff algorithms in action.
Conclusion
Diff algorithms stand as foundational tools in modern software development, significantly influencing how we track, understand, and collaborate on code changes. Throughout this exploration, we've seen how these computational methods have evolved from Hunt-McIlroy's pioneering work at Bell Labs to the sophisticated algorithms powering today's version control systems. Though Myers remains Git's default choice due to its speed and efficiency, patience diff offers compelling advantages when dealing with complex code reorganizations or refactoring.
The right algorithm choice ultimately depends on your specific needs. Myers works well for most everyday comparisons where performance matters, whereas patience diff shines during code reviews that involve substantial structural changes. Certainly, understanding these differences empowers developers to make informed decisions about which algorithm best suits their current task.
What matters most isn't merely finding differences between files but presenting those differences in ways that enhance human comprehension. After all, diff outputs primarily serve as communication tools between developers and their past or future selves. Accordingly, the most effective diff isn't necessarily the one with the fewest edit operations but rather the one that best represents the semantic changes you've made.
Rather than settling for default options, consider experimenting with different algorithms based on context. For routine changes, Myers might suffice, while patience diff could prove invaluable during major refactoring efforts. Try our Text Compare tool to see these diff algorithms in action. The small configuration change to set patience as your default (git config --global diff.algorithm patience) could dramatically improve your development workflow.
As software systems grow increasingly complex, the tools we use to understand changes must likewise evolve. Therefore, the humble diff algorithm—despite operating behind the scenes—remains a critical component of effective software development practices, worthy of thoughtful consideration rather than passive acceptance of defaults.
Key Takeaways
Understanding diff algorithms can dramatically improve your code review experience and development workflow by choosing the right tool for each situation.
• Myers algorithm (Git's default) prioritizes speed and works well for most comparisons, but can produce confusing diffs with refactored code
• Patience algorithm creates more human-readable diffs by matching unique lines first, making it ideal for complex code reorganizations
• Hunt-McIlroy was the pioneering algorithm from Bell Labs that laid the foundation for modern text comparison tools
• Switch to patience diff with git config --global diff.algorithm patience for better code review experiences
• The best diff algorithm isn't about minimal edits but about presenting changes that enhance human comprehension
The choice between algorithms should match your context: use Myers for routine changes where speed matters, but consider patience diff when reviewing substantial structural modifications or refactoring efforts.
FAQs
Q1. What is the default diff algorithm used by Git? The default diff algorithm in Git is Myers. It's a fast and efficient algorithm that works well for most general-purpose comparisons, but may sometimes produce confusing diffs when dealing with refactored code.
Q2. How does the Patience diff algorithm differ from other algorithms? The Patience algorithm prioritizes human readability by matching unique lines first. It's particularly effective for complex code reorganizations and refactoring, as it tends to produce more intuitive and cleaner diffs compared to other algorithms.
Q3. Can I change the diff algorithm Git uses? Yes, you can change Git's diff algorithm. For example, to set Patience as your default algorithm, you can use the command: git config --global diff.algorithm patience. This can significantly improve your code review experience.
Q4. What are the main advantages of the Myers algorithm? The Myers algorithm is known for its speed and efficiency. It performs well in most everyday comparisons and is particularly effective when comparing similar files. Its O(ND) time complexity makes it notably faster than many earlier implementations.
Q5. When should I consider using the Patience algorithm instead of Myers? Consider using the Patience algorithm when reviewing substantial structural changes or during major refactoring efforts. It's particularly useful when you need to preserve the structure of important content, such as function declarations, as it doesn't match trivial lines like lone brackets or blank lines.


